Regressione Lineare: predire le vendite
Ogni affarista che si rispetti dovrà prima o poi fare delle proiezioni di vendite: vuoi per ordinare il volume corretto dai fornitori, vuoi per dimostrare la validità del business ai finanziatori oppure per fare colpo con quanti affari farà il prossimo anno; le motivazioni sono molteplici e più o meno mondane. Ed ecco che il Data Scientist arriva in salvataggio! (E tornerà a casa con una bella parcella…)
Questo primo tutorial insegnerà proprio come, partendo da dati pre-esistenti, sia possible predire le future vendite di un business. Naturalmente, da buon accolito della statistica, non potrò esimermi da presentare la matematica sottostante: se ti annoia, salta alla sezione successiva dove mostrerò il lato pratico usando R.
1. Il Dataset
Il dataset che useremo si trova pre installato in R, ed è chiamato freeny. Di dimensioni 39×5 [39 righe/osservazioni x 5 colonne/variabili], rappresenta le vendite trimestrali di un non ben identificato business. Le variabili presenti sono:
- y: le vendite. Notate la notazione: in statistica/Data Science, y identifica sempre la variabile da predire, anche chiamata variabile dipendente o risposta (in inglese, dependent variable/response).
- lag.quarterly.revenue: le vendite del trimestre precedente.
- price.index: livello dei prezzi dei beni venduti.
- income.level: livello degli stipendi della clientela.
- market.potential: indice dell’attrattività del mercato.
Ecco una vista di come appare:

Nota: per creare modelli di forecasting utilizzeremo sempre dataset in forma matriciale.
2. La Regressione Lineare (LM)
la matematica no!
Come accennato precedentemente, il nostro obbiettivo è quello di predire le vendite per un trimestre futuro. Qual’è il ragionamento da seguire? Noi, esseri mortali, non conosciamo le vendite future dato che non si sono ancora verificate. Tuttavia, abbiamo a nostra disposizione una serie di altre variabili di cui conosciamo perfettamente il valore, anche futuro. In questo caso ad esempio, conosciamo le vendite passate (lag.quarterly.revenue), possiamo decidere che prezzo mettere (price.index), sappiamo il livello degli stipendi (income.level) tramite l’Eurostat e conosciamo anche il potenziale di un certo mercato (market.potential), magari tramite un sondaggio. Qual’è dunque il procedimento più logico per raggiungere il nostro obbiettivo? Spiegare le vendite come una funzione delle variabili a noi note; in altre parole, cercare una relazione tra le vendite e tutto il resto.
In Statistica, questo tipo di relazione, viene chiamato regressione. La forma funzionale più semplice è la seguente:

Dove:
: è il valore per le vendite (variabile dipendente) all’osservazione i, ossia alla riga i
: è il valore per una variabile indipendente (una di quelle che usiamo per predire) all’osservazione i
: è un parametro, anche chiamato intercetta (vedremo tra poco il motivo)
: è un altro parametro, anche chiamato pendenza, che rappresenta il cambio di y per ogni unità di differenza in x. Ossia se
: i residuali, la componente casuale, che riamane insperata dal modello.
Gli amanti della geometria noteranno che tale funzione non è altro che una retta (da qui i termini ‘intercetta’ e ‘pendenza’). E infatti, quello che cerchiamo di fare è proprio questo: cercare di creare una retta che si adatti il meglio possibile ai dati.
Ad esempio:

visualizza la relazione esistente tra le vendite e il livello degli stipendi. Come possiamo vedere, essa non è una retta perfetta: questo perché c’è ovviamente una componente aleatoria nella relazione. Costruendo una retta perfetta che si adattati al meglio a questi dati, andremo proprio a separare la relazione ‘vera’ dalla componete aleatoria; separeremo il segnale dal rumore di fondo, che è casuale. Ecco il risultato di questo procedimento:

Per costruire questa retta dobbiamo ‘aggiustare’ i due parametri 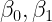
Ossia usando il metodo dei least squares, i quadrati minimi; minimizzando questo tizio qui:

Questo caso con una sola variabile indipendente può essere poi generalizzato a più variabili:

La logica è sempre la stessa, anche se ora è impossibile visualizzare la relazione con un grafico (il massimo possibile sono 3 dimensioni. Per ovvie ragioni).
Naturalmente, come ogni elemento statistico, anche i parametri della regressione avranno una componente di variabilità, rappresentata dalla loro varianza e deviazione standard.
Inoltre, i modelli di regressione lineare semplice sono basati su quattro assunzioni:
- Normalità degli errori
- Deviazione standard degli errori
- Linearità della relazione tra le variabili.
- Indipendenza degli errori.
Data la vastità dell’argomento, delle assunzioni parleremo più nel dettaglio in un articolo successivo.
3. In R
Finalmente la pratica.
La regressione lineare semplice, in R, richiede ben pochi sforzi. La funzione da utilizzare è lm() nel pacchetto di {stats} (che è già preinstallato).
Per creare il modello basta dunque scrivere :
attach(freeny) # Per caricare il dataset
View(freeny) # Per visionare il dataset in forma matriciale
modello = lm(y~., data = freeny) # Per creare il modello
Il modello cosí creato avrà y come variabile dipendente e tutte le altre (il ‘.’) come indipendenti.
Per visionare il contenuto, ovvero i parametri del modello, la loro variabilità e i relativi p-value, bisogna utilizzare la funzione summary():
summary(modello)
Ecco l’output:

Come possiamo vedere, la variabile log.quarterly.revenue, quando tutte le altre variabili sono presenti, non risulta avere una relazione statisticamente significativa con le vendite.