In un articolo precedente abbiamo descritto la meccanica di un modello lineare. Come accennato, questi modelli sono costruiti su quattro assunzioni (because there’s no free lunch):
- Normalità degli errori
- Deviazione standard degli errori costante
- Indipendeza degli errori
- Linearità della relazione tra la risposta e le variabili indipendenti
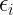
La violazione di questi requisiti causa conseguenze più o meno gravi sull’affidabilità del modello. Tuttavia, grazie a vari test, è possibile identificare e controllare se tali violazioni esistano. Nei paragrafi seguenti si illustrerà come eseguire questi test con R e la relativa matematica sottostante.
Da tenere a mente: gli errori di un modello sono definiti come:
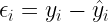
dove:
: è il valore i della risposta osservato.
: è il valore i della risposta predetto dal modello.
Solitamente, per controllare queste assunzioni, gli errori devono essere standardizzati, ossia ridotti a seguire una distribuzione Normale con media 0 e dev standard uguale ad 1.
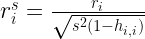
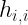
Normalità
Gli errori dovrebbero essere approssimativamente distribuiti secondo una Normale con media zero e deviazione standard 
Il test visivo consiste nel creare un QQ Plot, ossia raffigurare gli errori standardizzati contro un campione casuale di una N(0,1): se gli errori sono Normalmente distribuiti, essi devono posizionarsi sulla diagonale del piano:

Come test numerico invece, esistono numerose alternative (e siete liberi di procedere come meglio preferite). Per quanto mi riguarda uso (quasi) sempre il Shapiro-Wilk dove H0 è ‘Normalità rispettata’. In R:
shapiro.test(residuals(linearModel))
dove shapiro.test() è la funzione del test vera e propria e residuals(linearModel)) calcola gli errori per il nostro modello lineare.
La normalità tuttavia non è un’assunzione critica; violazioni minime possono essere comunque considerate accettabili.
Linearità
Per un modello lineare semplice, deve esistere una relazione lineare tra ogni variabile indipendente e quella dipendente. Per controllarla, basta un grafico della variabile in questione contro la dipendente: i punti devono posizionarsi in lungo una linea retta.
Omoschedasticità
Ossia varianza degli errori costante (chiamarla omoschedasticità però vi farà sembrare molto più professionali). Per controllarla, è necessario il test di Breusch-Pagan, dove H0 è ‘omoscedasticità rispettata’.
In R: ncvTest(linearModel)
Varianza degli errori costante è un’assunzione critica per un modello statistico: se non è rispettata può portarci a concludere che alcune variabili indipendenti siano utili per spiegare la dipendente, quando in realtà non lo sono. Ossia, ci può portare a trarre conclusioni errate sulle relazioni tra le variabili. Per risolvere questo problema, bisognerà abbandonare il modello lineare semplice per avventurarsi con qualche altro strumento (un GLS per esempio).
Indipendenza
Per indipendenza si intende che l’errore i non deve essere correlato all’errore i + 1. Per controllarla, anche in questo caso, è possibile eseguire un test: il Durbin-Watson.
In R si esegue cosí durbinWatsonTest(linearModel).
L’indipendenza è un’altra assunzione critica. Come per l’omoschedasticità, violazioni possono portare a erronee stime delle deviazioni standard, con conseguenti errori nei test di significatività. Un GLS potrebbe di nuovo essere una soluzione.