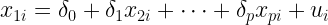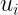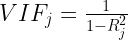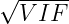Una volta costruito un modello lineare col metodo di Maximum Likelihoodcome si può decidere quali variabili introdurre nel modello? Ovviamente, noi vogliamo introdurre variabili dipendenti che:
abbiano una relazione genuina con la variabile dipendente
aggiungono informazione al modello, considerando le altre indipendenti già presenti nel modello.
Ovviamente, vorremmo allo stesso tempo escludere variabili che forniscono la stessa informazione di quelle già presenti; ossia, vogliamo evitare la collinearità.
Collinearità
Quando variabili collinari sono inserite insieme in un modello, quest’ultimo risulta instabile e otterremo errori standard maggiorati per i parametri. La collinearità può essere individuata tramite i Variance Inflation Factors (VIFs).
I VIFs si calcolano costruendo un modello lineare tra ogni covariata e tutte le altre covariate. Ad esempio, per la prima variable indipendente
dove è l’errore.
Un modello di questo tipo è costruito per ogni indipendente e prendendo l’R2 si calcola il VIF:
per le covariate j = 1, . . ., p.
Grandi VIFs indicano collinearità. Tuttavia non ci sono regole ben precise sul ‘grandi’: la regola più comune è di considerarli problematici quando VIF > 4, perché l’intervallo di confidenza (IC) del parametro j sarà grande il doppio del normale (ossia indica quanto sarà dilatato l’IC)
Facciamo un esempio in R:
LinearAll = lm(Sepal.Length ~ Sepal.Width + Petal.Length + Petal.Width, data = iris) # Creiamo il modello lineare
library(car) # Carichiamo la libreria per la funzione 'vif'
vif(LinearAll)
Come possiamo vedere le variabili ‘Petal.Length’ e ‘Petal.Width’ sono altamente collineari: se le togliessimo otterremo una maggiore stabilità del modello
Un’altra prova del fatto che che il modello sia affetto da collinearità sono parametri il cui valore cambia sostanzialmente quando nuove variabili sono aggiunte al modello.
Come risolvere la collinearità? La soluzione più semplice è di rimuovere le variabili collinari: molto spesso questo accade automaticamente quando si usano algoritmi di selezione automatica.
O anche: ‘La Statistica è morta. Lunga vita alla Statistica!’
I recenti sviluppi politici mondiali hanno sicuramente confuso i più riguardo cosa sia cambiato nella mente dell’elettorato, sul perché idee apparentemente irrazionali1e populiste abbiano avuto il sopravvento. L’evento più lampante (se non folkloristico) è stata l’esclamazione di Gove, un politico sostenitore della Brexit:
Britain has had enough of experts
Questa frase, oltre ad avere un significato filosofico profondo, ha anche dei risvolti sinificativi a livello statistico, perché riflette la sfiducia del cittadino contemporaneo nella misurazione quantitativa dello realtà, ossia la Statistica.
Un recente articolo apparso sul Guardian ha per l’appunto affrontato questo tema, che risulta essere epocale, tanto da aver generato il neologismo di post-verità.
Uno studio di Marketplaceha rilevato come il 47.5% dell’elettorato Trump e il 25% del totale “non crede ai dati economici ufficiali pubblicati dal governo federale”.
Risultati studio Marketplace sull’elettorato americano
Allo stesso modo, in un altro studio YouGov/Uni Cambridge, il 55% dei rispondenti crede che “il governo stia nascondendo il numero reale di immigrati viventi nel paese”.
Pare dunque ovvio che il pubblico occidentale non creda più all’oggettività della misurazione e al metodo scientifico della Statistica. Non solo, sembra anche, come risulta dalle parole di Gove, che tale oggettività risulti arrogante e debba essere combattuta; ecco dunque che gli unici argomenti che contano sono solo soggettivi e altamente personalizzati.
Un esempio? Un report del think-tank BritishFutureha dimostrato come le persone siano emotivamente colpite da storie personali e struggenti di immigrati; al contrario, i “freddi” dati generano l’effetto diametralmente opposto, soprattutto se dimostrano l’influenza positiva degli immigrati sull’economia. La motivazione? Le persone assumono automaticamente che siano dati contraffatti.
Si potrebbe discutere per ore sulle motivazioni profonde di questa ostilità verso i dati statistici ufficiali (una mia spiegazione personale e ‘a pelle’ è che il bias di confermasia più forte di quanto pensiamo), ma forse questa non è la sede più adatta.
Tuttavia, voglio sottoporci ad un esperimento mentale riguardo le implicazioni statistiche di questo fenomeno: e se avessero ragione? Ossia, se i dati fossero davvero non rappresentativi della realtà?
Questa domanda fa riflettere in maniera profonda sulla natura dei dati statistici: essi sono infatti nati per riassumere la stocasticità del mondo in maniera oggettiva ed inequivocabile. Esistono proprio per demolire la diversità e riassumerla in una piccola panoplia di numeri in modo tale da ‘rendere’ la realtà più semplice ed interpretabile dalle nostre menti limitate. Il problema però, è che seppur la nostra rappresentazione del mondo è ora semplice, il mondo rimane complesso, qualsiasi modello tu voglia usare. Esempio lampante in statistica economica: il GDP misura davvero la produzione di un paese? A che geografia è meglio produrlo? Nazionale? Regionale? Che cosa vogliamo contarci dentro: produzione metallurgica? Prostituzione? E i lavori domestici?
Ecco dunque l’insegnamento centrale della Statistica, che a mio avviso dovrebbe essere insegnato prima ancora dei numeri aleatori:
la Statistica è un compromesso tra il comprendere e il descrivere.
Più la descrizione è dettagliata, meno è comprensibile, e vice versa. Non a caso esistono misure come R2 o la Devianza, proprio per aiutarci a scegliere un livello di questo compromesso. Ma ancora: sono di nuovo misure, usate per misurare altre misure. Sta al Data Scientist, allo Statistico l’onere di scegliere, di valutare tutte queste misure, perché da soli i numeri non vogliono dire nulla: la magia sta tutta qui, nell’esperienza dell’analista che usa una mente umana per cercar di comprendere la stocasticità dell’esistenza.
Resta solo da vedere che strada prenderanno le nuove tendenze Statistiche come la Machine Learning e la Data Science, che creano delle vere e proprie macchine automatiche: la seconda vita della Statistica; dai semplice numeri, alle macchine.
E intanto, il mondo resta comunque casuale, in barba a tutti noi.
Note
1. Seppur io faccia fatica a non esprimermi a livello politico, cerco di resistere alla brama.
Il mese scorso ad Edinburgo si è tenuta l’annuale Scottish Governement Statistical Conference. Il contenuto delle presentazioni è stato più amministrativo che tecnico: gli oratori hanno di fatto presentato la strategia Open Data e il nuovo sistema organizzativo del dipartimento statistico del governo.
In mezzo a tutta ‘sta noia però, si è anche tenuta una sfida poetica: ogni partecipante alla conferenza poteva inviare una poesia alla giuria, a patto fosse di contenuto statistico.
Orbene, come immaginerete non ho potuto esimermi dalla tentazione di diventare un Omero statistico per consegnarmi alla Gloria eterna. Ecco dunque il testo incriminato:
The Outlier legacy (or violation of Normality)
Unmodelled by LM:
Thou, be not like the Median,
but a Life of Deviance.
Ovviamente, quando morirò, qualche critico scoprirà questa poesia e scriverà pagine e pagine di interpretazione rompendo i maroni a poveri studenti liceali.