In questo articolo vi darò la notizia che ciascuno di voi aspettava. La grandiosità del calcolo matematico unito al potere di calcolo automatico: la selezione automatica di variabili. Ossia, è possibile far selezionare dal computer la combinazione di variabili ottimale per un modello.
L’argomento si innesta su quello dell’articolo precedente, in cui abbiamo illustrato la collinearità.
Esistono tre metodi si selezione automatica di variabili:
- Eliminazione all’indietro
- Selezione in avanti
- Selezione progressiva
Ognuno di questi metodi ha i suoi vantaggi e svantaggi:
Eliminazione all’indietro
Inizia con il creare il modello più complesso possibile, ossia introducendo tutte le variabili disponibili. Ad ogni passo elimina la variabile ‘meno importante’ fino a raggiungere un punto di ottimo usando una certa misura (vedi dopo).
Selezione in avanti
Inizia con il modello più semplice che esiste: solo con l’intercetta. Ad ogni passaggio aggiunge una variabile ‘importante’ fino al raggiungimento di un punto di ottimo.
Selezione progressiva
Combina i due metodi precedenti, cercando ad ogni passo variabili da escludere ed includere. È significativamente più calcolo intensivo.
Se tuttavia vogliamo automatizzare questi algoritmi, ‘l’importanza’ di ogni variabile deve essere misurata in modo oggettivo. Per fare ciò esistono innumerevoli metriche; quella più semplice ed usata si chiama AIC (Aikake Information Criterion). L’AIC è una misura di bontà di predizione penalizzata dal numero di variabili contenute nel modello. Quindi un AIC piccolo segnala un modello migliore. Bisogna tuttavia ricordare che l’AIC è una misura relativa e non assoluta. Formalmente:
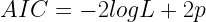
dove:
- logL (log-likelihood) è una misura di bontà (ne parleremo in seguito)
- p è il numero di variabili nel modello statistico.
Un’altra misura molto usata è la BIC (Bayesian Information Criterion), che utilizza un penalità che cambia con la grandezza del campione:
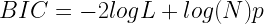
Dove:
- N è la grandezza totale del campione.
Gli algoritmi di selezione automatica usano quindi queste misura (e altre simili) per dare un rango ad ogni modello (ognuno con una diversa combinazione di variabili) e scegliere quello migliore.
Ovviamente, questi algoritmi automatici sono totalmente indipendenti dal contesto in cui il modello viene creato, i.e. non tengono in considerazione l’ambito scientifico del modello. È qui che il Data Scientist deve usare la sua esperienza ed arte per decidere come agire. L’analista deve dunque capire se prediligere la capacità predittiva (e quindi rischiare di introdurre troppi parametri) o scegliere la capacità descrittiva ed includere solo variabili scientificamente significative.
Largo ad R!
AIC e BIC possono essere calcolati usando queste funzioni, entrambe nel pacchetto {stats}
AIC(object, ...)
BIC(object, ...)
Per la selezione automatica si usa invece questa, sempre nel pacchetto {stats}:
step(object, scope, scale = 0,
direction = c("both", "backward", "forward"),
trace = 1, keep = NULL, steps = 1000, k = 2, ...)
È anche possibile utilizzare la funzione dredge nel pacchetto {MuMIn} che permette la scelta di misure diverse oltre all’AIC.
Ecco un esempio completo di Selezione Progressiva usando il dataset freeny:
Il codice
linearAll = lm(y~., data = freeny)
step.linearALL = step(linearAll, direction = "both")
e l’output

Come vediamo, il modello migliore è con tutte le variabili tranne lag.quarterly.revenue: non includerla produce il più basso AIC possibile.