
Stimare lo stock minimo delle materie prime è una procedura difficile e suscettibile ad errori, soprattutto se eseguita con metodi euristici.
Per fortuna, la statistica ci salva ancora una volta, assicurandoci un livello ottimale di stock e massimizando i risparmi dell’inventario.
Il problema
Come si presenta il problema? Abbiamo 3 variabili da considerare:
- Tempi di riordino (in questo esempio, 10 giorni di lead time)
- Il consumo storico
- Il Lean Manager che ti rincorre nel panico
Per l’esempio di questo post, il prodotto da stoccare saranno fogli di lamiera (misuarti in Kilogrammi), con un tempo di riordino di 10 giorni.
Exploratory Data analysis

Un semplice grafico (Fig. 1) del consumo lamiera contro le decine dei giorni ci presenta una stagionalità abbastanza marcata: sarebbe dunque opportuno ottimizzare seguendo la variabile temporale, in modo da risparmiare sull’inventario.

Se eseguiamo un istogramma del consumo lamiera, la distribuzione è inoltre chiaramente approsimabile da una Gamma.
Siamo fortunati: possiamo già azzardare un modello.
Il modello
Come creare una stima per gli stock minimi? Un problema simile è facilmente risolvibile con il concetto di intervallo di confidenza (IC).
Possiamo quindi calcolare il consumo medio di lamiera data la variabile temporale, ossia la soluzione al problema risulta costruire un intervallo di confidenza (IC) intorno a:
![E[Y|(X,\omega)] = \mu_{Y|(X, \omega)}](http://s0.wp.com/latex.php?latex=E%5BY%7C%28X%2C%5Comega%29%5D+%3D+%5Cmu_%7BY%7C%28X%2C+%5Comega%29%7D&bg=ffffff&fg=000&s=2&c=20201002)
Dove:
- Y è il consumo di metallo
- X è la matrice delle variabili indipendenti (i.e. l’indice del periodo di 10 giorni)
- ω è il codice prodotto (in questo caso solo un tipo di lamiera)
- μ indica la media
Per stimare questa media, è necessario fittare un GLM con famiglia Gamma e link-function logaritmica:
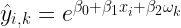
Ricordo al caro lettore che a livello della link-function, la realtà è Normale. Dato ciò, costruire un IC α è banale: bisogna solamente eseguire il classico calcolo con la distribuzione t (perchè la dev std della popolazione non è nota, mascalzone!)
Il GLM (e il così costruito IC), ci stimano il consumo medio per periodo: dunque, il limite massimo di tale IC risulta essere la scelta migliore per lo stock minimo.
Ovviamente, la decisione del Lean Manager risulta ora concentrata sulla scelta del parametro α.
Ed ecco a voi il risultato:

Per una trattazione più matematicamente rigorosa del problema, potete riferirvi al mio GitHub, dove troverete la documentazione del progetto. Qui in calce, invece, troverete il codice usato.
set.seed(123)
# Prototyping for Minimum stock of metal sheets
lamiera <- read.csv2("foo/Lamiera.csv", sep= ";", dec = ",")
lamiera <- lamiera[lamiera$Year >= '2014',] # Only considering years 2014 onwards. By EDA boxplot(quantity~Year), 2014 is the first year of greater variability
# Fitting model: glm, Gamma distr with log-link function
lmTest <- glm(Quantity~as.factor(TenDaysOfYear)+as.factor(PartNo), data = lamiera, family= Gamma(link= 'log'))
# Estimating CI and plotting
alpha <- 0.98 # Significance level
codiciLamiera <- unique(lamiera$PartNo)
for(codLamiera in codiciLamiera){
preddata <- data.frame('TenDaysOfYear' = seq(1,36, by=1), 'PartNo' = codLamiera)
preds <- predict(lmTest, newdata = preddata, type = "link", se.fit = TRUE)
critval <- qt(alpha, nrow(lamiera)-1)
upr <- preds$fit + (critval * preds$se.fit)
lwr <- preds$fit - (critval * preds$se.fit)
fit <- preds$fit
fit2 <- lmTest$family$linkinv(fit)
upr2 <- lmTest$family$linkinv(upr)
lwr2 <- lmTest$family$linkinv(lwr)
name <- paste('foo/Lamiera.csv','lamiera_', codLamiera,'.png', sep = '')
png(filename = name)
plot(Quantity~TenDaysOfYear, data= lamiera[lamiera$PartNo == codLamiera,], main=codLamiera)
lines(upr2, col="red")
points(fit2, col="green")
dev.off()
name <- paste('foo/Lamiera.csv','lamiera_', codLamiera,'.csv', sep = '')
preddata$PredictedConsumption <- round(fit2, 2)
preddata$MinimumStock <- round(upr2, 2)
write.csv2(preddata, file = name, row.names = F)
}
# Model checks: all assumptions are well respected
plot(rstandard(lmTest), ylab = "Standardized residuals") # Super-nice looking plot: homoschedasticity respected
resOrdered <- rstandard(lmTest)[order(lamiera$TenDaysOfYear)]
plot(1:nrow(lamiera), resOrdered) # Independence respected
hist(rstandard(lmTest), main="Distribution of standardized residuals", xlab="Standardized residuals")
qqplot(rnorm(length(rstandard(lmTest))) ,rstandard(lmTest), xlab = "Std Normal sample", ylab = "Standardized residuals")
abline(c(0,1), col= "red")# Normality respected
plot(fitted(lmTest), residuals(lmTest, type = "pearson"), xlab = 'Fitted values', ylab = 'Pearson residuals') # mild pattern of pearson residuals, but can be overlooked due to big sample size
# Linearity: respected by construction (i.e. scale of link is always linear)