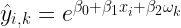Predirre le vendite è il sogno più bagnato di ogni manager che si rispetti. Difatti, avere stime affidabili sull’andamento del mercato è la chiave del budgeting: più le stime sono corrette, più la programmazione diventa facile ed effettiva.
Come in ogni problema di predizione, la variabile che influisce di più sulla bontà del modello è l’informazione disponibile. Nella mia esperienza lavorativa, la quasi totalità delle aziende ha (per ora) una cultura del dato molto scarsa, se non nulla. Il data scientist si troverà dunque a dover lavorare con dati parziali, da reclamare tramite molteplici fonti, la cui affidabilità sarà semplicemente dubbia. Ovviamente, tale ostacolo è prettamente individuale e varierà da scenario a scenario: è dunque fuori dallo scopo di questo post.
Quello di cui voglio veramente parlare è come approcciare the algoritmic side of thigs . Ordunque, vi presento qui uno scoppiettante programmino per affrontare il forecasting delle serie storiche come dei veri pro.
Le basi
Il problema può essere affrontato in base a due variabili interdipendenti:
- La finestra di predizione
- Il lag delle variabili
La finestra di predizione rappresenta con quanto anticipo vogliamo predirre Y (e.g. se la predizione ha 3 mesi di anticipo, la finestra sarà di 3 mesi). Il lag delle variabili rappresenta invece la relazione temporale con cui le variabili indipendenti influenzano la dipendente. Ad esempio: le vendite di un’industria metallurgica saranno influenzate dall’andamento del PIL globale. Ma questa relazione non sarà immediata temporalmente: l’aumento di domanda del metallo sarà successivo di x mesi all’aumento del PIL.
Mentre la finestra di predizione è decisa dal Data Scientist e dal management, il lag delle variabile è fondamentalmente ignoto. Per trovarlo, in maniera ottimale, si ricorre alla Cross Validation. L’approccio che io propongo è univariato.
Restate con me, così vi spiego le funzioni per questo scopo.
L’oracolo algoritmico
Il programma è costituito da tre funzioni:
- laggedDataMat: lagga il dataset (ossia “sposta” le variabili di un determinato lag)
- bestLagRegr: trova il lag ottimale (univariato) per ogni variabile
- modelSelection: prende l’outup di bestLagRegr ed esegue una grid search per trovare l’ottimale modello predittivo
Le librerie richieste per l’esecuzione sono:
import numpy as np, pandas as pd, pickle, copy
from sklearn.model_selection import cross_val_score, TimeSeriesSplit, GridSearchCV
from sklearn import ensemble
from sklearn.ensemble import GradientBoostingRegressor
Ecco qui di seguito le funzioni in Python:
laggedDataMat
def bestLagRegr(dataMat, maxLag, minLag, yName):
# Purpose: identify the best lag for variables to be used in regression. Uses CrossValidation
# (folds TimesSeriesSplit)
# data - a panda DF with named columns
# maxLag - the maximum lag to be tested. Integer
# minLag - the minimum lag to be tested. Integer
# yName - the name of the column of 'data' containing the dependent var. String
data = dataMat.copy()
colnames = [y for y in data.columns if y != yName]
lags = range(minLag, maxLag)
folds = TimeSeriesSplit(n_splits=int(np.round(data.shape[0] / 10, 0)))
results = {}
for col in colnames:
scores = []
lags_list = []
for l in lags:
varname = col + str('_lag') + str(l)
data[varname] = data[col].shift(l)
YX = data[[yName, varname]]
YX = YX.dropna().as_matrix()
# Build regressor and estimate metric of prediction performance with CV
regr = ensemble.GradientBoostingRegressor(learning_rate=0.01, max_depth=1, n_estimators=500)
perform = cross_val_score(regr, X=YX[:, 1].reshape(-1, 1), y=YX[:, 0], cv=folds,
scoring='neg_median_absolute_error')
# Store scores result and lags
scores.append(np.median(perform))
lags_list.append(l)
# Calculate best score, corresponding best lag and store it in a dictionary, containing all colnames
best_score = max(scores)
best_lag = lags_list[scores.index(best_score)]
results[col] = [best_lag, best_score]
return(results)
bestLagRegr
def laggedDataMat(dataMat, yName, lagsDict):
# Purpose: build a lagged DF
# dataMat: the unlagged DF with named columns
# yName: name of the dependent var. String
# lagsDict: dictionary produced with 'bestLagRegr, containing:
# - keys: column names of dataMat
# - elements: lists with lag, CV score
#
# Output: a panda DataFrame with columns order sorted alphabetically
# Initialize empty DF
df = pd.DataFrame(index=dataMat.index)
# Set dependent var
df[yName] = dataMat[[yName]]
# Creating and adding the lagged vars
for colName in lagsDict.keys():
l = lagsDict[colName][0]
colNameLag = colName + str('_lag') + str(l)
df[colNameLag] = dataMat[[colName]].shift(l)
df = df.sort_index(axis=1)
return(df)
modelSelection
def modelSelection(maxLag, data, depVar, toSave, pSpace = None, alpha = 0.95):
if pSpace is None:
pSpace = dict(n_estimators=list(range(5, 2000, 10)),
learning_rate=list(np.arange(0.001, 1, 0.1)),
max_depth=list(range(1, 3, 1)))
lags = range(1, maxLag)
results = dict()
for lagMin in lags:
print('Esimating model for lag: ', lagMin)
lagAnalysis = bestLagRegr(data, maxLag, lagMin, depVar)
lagMat = laggedDataMat(data, depVar, lagAnalysis)
lagMat = lagMat.dropna()
trainY = np.ravel(lagMat[depVar])
lagMat = lagMat.drop([depVar], 1)
folds = TimeSeriesSplit(n_splits=int(round(lagMat.shape[0] / 10, 0)))
model = GradientBoostingRegressor(loss='ls')
regr = GridSearchCV(estimator=model, param_grid=pSpace, scoring='neg_mean_squared_error', cv=folds)
regr.fit(lagMat, trainY)
modelName = toSave + '/' + 'modelOI' + '_lag' + str(lagMin) + '.sav'
pickle.dump(regr.best_estimator_, open(modelName, 'wb'))
temp = dict(BestModel=regr.best_estimator_, Score=regr.best_score_, Lags=lagAnalysis)
regrQUpper = copy.deepcopy(regr.best_estimator_)
regrQUpper.set_params(loss='quantile', alpha=alpha)
regrQUpper.fit(lagMat, trainY)
temp['QUpper'] = regrQUpper
regrQLower = copy.deepcopy(regr.best_estimator_)
regrQLower.set_params(loss='quantile', alpha=(1-alpha))
regrQLower.fit(lagMat, trainY)
temp['QLower'] = regrQLower
key = 'Lag ' + str(lagMin)
results[key] = temp
return(results)




![E[Y|(X,\omega)] = \mu_{Y|(X, \omega)}](http://s0.wp.com/latex.php?latex=E%5BY%7C%28X%2C%5Comega%29%5D+%3D+%5Cmu_%7BY%7C%28X%2C+%5Comega%29%7D&bg=ffffff&fg=000&s=2&c=20201002)